Can Your DataOps Platform Do This?
It feels like it has been ages since I last posted! I have been working on a lot of cool...

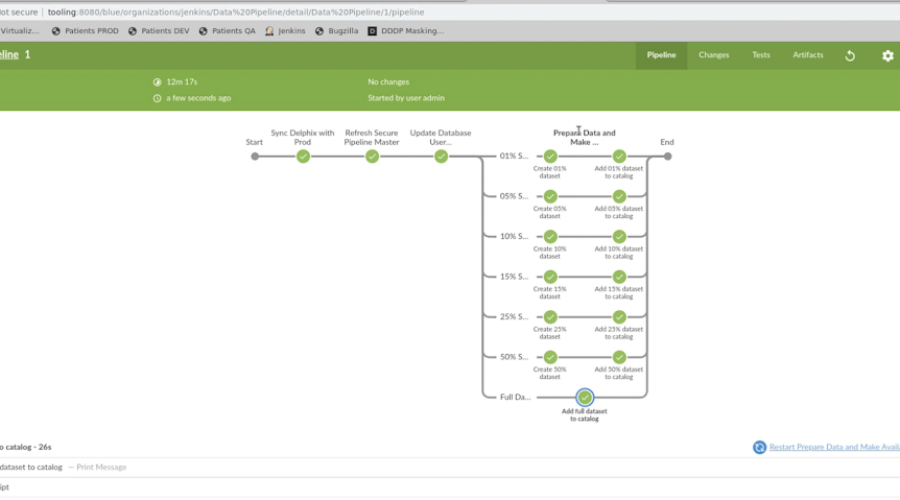
It feels like it has been ages since I last posted! I have been working on a lot of cool...
It has been almost 2 years since I penned Want to be Great? Always Touch the Fantastic Line: a story about...
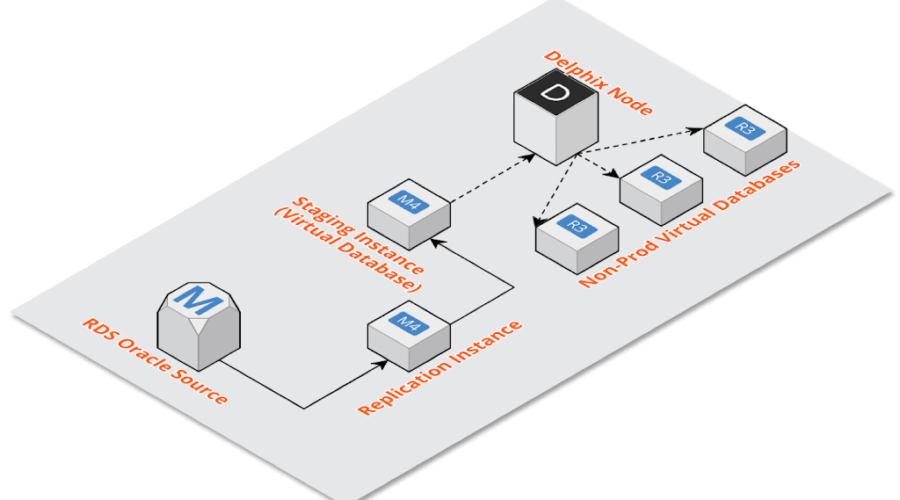
Architecture diag from delphix.Last year Delphix blogged about how the Dynamic Data Platform can be leveraged with Amazon's RDS (link...
Test environment data is all over the place, slowing down your projects, and injecting quality issues. It doesn’t have to...
Continuous — (adj.) forming an unbroken whole; without interruption.Continuous Integration and Continuous Deployment are two popular practices that have yielded huge benefits...
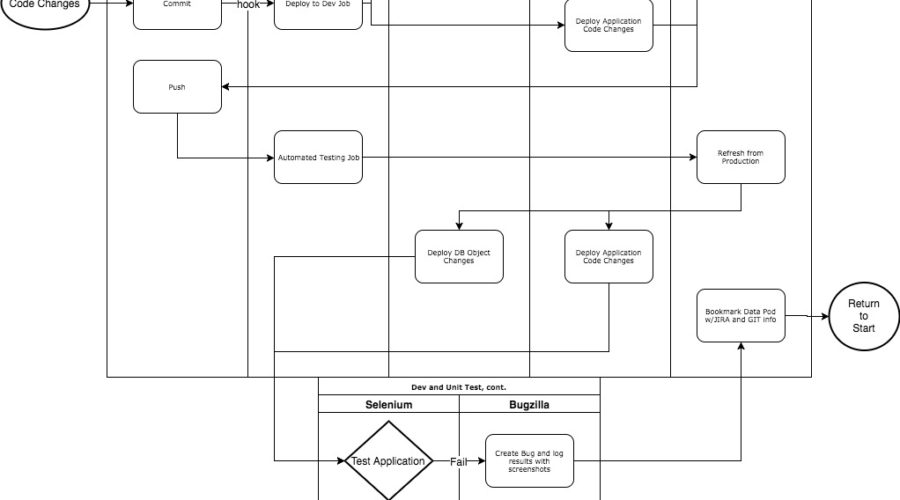
Hey Everyone!I know I have been talking about this for a while, but with the DevOps Enterprise Summit kicking off,...
Hey everyone! I’m back in the “demonstration saddle” again to showcase how easy it is to replicate data from one...

bigstock/monsitjThe explosion of data in the recent years has had some knock-on effects. For example:Data theft is far more prevalent...

Last week, Delphix held its annual Company Kickoff (CKO). It reminded me of what makes Delphix such a fantastic company,...

Not my problem (NMP) - (n) a statement, or position, of apathy expressed by those who perceive they are external...
© 2024 — Adam Bowen
Created with in Ashland, KY. Theme by HB-Themes.
Recent Comments